
一些高级语法
堆和栈
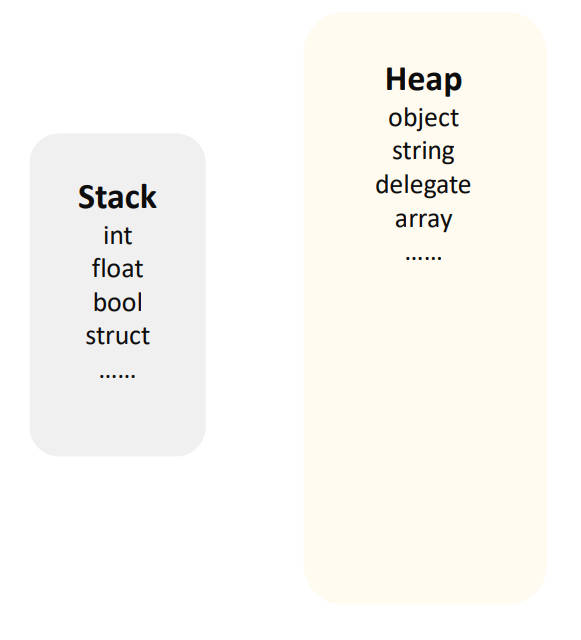
栈(Stack)是一块较小的区域,其大小是固定的,一般在1-2MB之间。其中主要存储 本地变量。栈的访问速度非常快。
堆(Heap)是一块较大的区域,其中主要储存我们用new关键字创建出的类的实例。 它的大小是随着我们的使用不断增长的,最大可达到绝大部分进程可用内存。但是 堆的访问相较栈要慢很多。
值类型 Value Type
在C#中,数据类型分为两大类:值类型(value type)和引用类型(reference type)。 它们的区别主要在数据的存储方式与变量之间的数据传递方式:
值类型直接存储数据,并且变量之间是通过拷贝的方式传递的。
比如int是值类型,那么考虑以下的代码:
int a=7;
int b=a;
b=-1;
很明显,通过修改b的值是不能影响到a的值的。(尽管我们写了int b = a) 这是因为a这个变量中直接存储了‘7’这个数据,而b = a实际上是把a中的值拷贝了一份再复制给b的。所以b和a没有直接的联系。
值类型的数据是存储在栈(Stack)上的!
常见的值类型有:所有的基本数据类型(int, float, double, bool, long, char, etc.)、枚举类型(enum)、结构体(struct)
引用类型 Reference Type
引用类型与值类型很不同,它并非直接存储数据本身,而是存储了指向该数据的地址。 引用类型的变量之间传递数据时只是拷贝了其地址,并没有拷贝数据本身。所以自始至终只会有一份数据。
//Transform是引用类型,考虑以下代码:
Transform tf1 = object1.transform;
Transform tf2 = tf1;
tf2.position = new Vector3(1,0,0);
//我们通过修改tf2的position会影响到object1的位置吗?会!
//这是因为tf1和tf2中只存储了指向object1.transform的地址。tf2=tf1这行代码仅拷贝了地址,并没有拷贝object1.transform本身,所以tf2和tf1指向的是同一个物体。
引用类型本身是存储在栈(Stack)上的,而引用类型所指向的数据是存储在堆(Heap)上的!
所有的引用类型都继承自System.Object类。
常见的引用类型有:类(class)、字符串(string)、数组(与数组的元素类型无关)、委托(delegate)
C#中的string
string是一种引用类型,但它有许多特别之处,使得它有时会显得和值类型很像。
不变性(Immutability)
C#中的string是不变的。这意味着当一个string被创建时,它就永远不能被改变了。而我们对string进行的任何修改操作其实都 是创建了一个新的字符串变量。
比如string s = “123”; s+=“4”; 我们其实创建了两个string:”123” 和 ”1234”。s这个变量最后指向的是”1234”,而一开始 的”123”这个字符串就变成了“垃圾”。
String Interning
当我们频繁地引用一个内容相同的字符串时(比如在Update里写string s = “a”),难道系统会需要不断创建新的字符串吗?
这 未免有些浪费了。 于是,C#内置了string interning机制。
它很像一个“字符串池”,当我们想要引用一个字符串时,如果池中已经有内容相同的字 符串,我们可以直接访问该已存在的字符串,不需要创建新的字符串。
string str1 = "Hello";
string str2 = "Hello";
bool areEqual = Object.ReferenceEquals(str1, str2);
//areEqual为true!
ref 关键字
C#中函数的参数可以被ref关键字修饰。它允许我们在传参时使用变量的引用,而非变量的值。
(一般来说,我们向函数中传参数时都是复制了一份变量的值并传入的。这也是为什么函数内的变量通常和函数外的变量没关系。)
int a = 1;
AddOne(a);
print(a); // a=1
……
void AddOne(int a)
{
a++;
}
//参数“a”是通过值传递的,和函数外的“a”完全没关系。
int a = 1;
AddOne(ref a);
print(a); // a=2
……
void AddOne(ref int a)
{
a++;
}
//有了ref关键字后,参数“a”是通过引用传递的。于是函数内的“a”和函数外的“a”是一个东西了。
string s = “123”;
Append(ref s);
print(s); // s=“123a”
……
void Append(ref string s)
{
s+=“a”;
}
//同样,这里函数内外的“s”也都是同一个东西了。
装箱与拆箱
装箱(boxing):从值类型转换到引用类型;拆箱(unboxing):从引用类型转换到值类型。
这是一个性能消耗较大的操作,应尽可能减少。
//装箱
int a = 7;
object o = a;
//拆箱
object o = 42;
int a = o;
GC:垃圾回收机制
我们一直在用new来在堆上创建新的物体,但从来不需要主动删除物体。难道内存一直会越来越挤,直到被用完吗? 当然不!
为此,C#提供了垃圾回收器(Garbage Collector)来帮助我们清理不需要的内存。
堆中的内存是分为3个Generation的!
Generation 0:主要为临时变量、刚刚被创建的(较小的)类的实例。这里的清理频率是最高的。
Generation 1:这是一个缓冲区,从gen0中“存活下来”的物体会被放入gen1。(这说明它们更常被使用)
Generation 2:从gen1中“存活下来”的物体会被放入gen2。这里主要为长期需要的变量(static变量等),清理的频率最低。
当第k个generation被GC清理时,所有小于k的generation也都会被一并清理。 所以当GC清理gen2的时候可以被认为是一个“完整的垃圾回收”。
一次垃圾清理分为三个阶段。
-
标记阶段(Marking Phase) 在这个阶段,GC会找出并标记所有仍被引用的物体。(也就是说我们依然在使用它们)
这是通过一个“引用树”(Reference Tree)实现的:每一个引用类型的数据都“继承”自一个根节点,而这些物体之间的引 用关系构成了一个树状结构。
void Mark(objectRef o)
{
if (!InUseList.Exists(o))
{
InUseList.Add(o);
List refs = GetAllChildReferences(o);
foreach (objectRef childRef in refs)
{
Mark(childRef);
}
}
}
//可以看到,这是一个递归的操作。我们可以从根节点开始逐渐探索到整个树状结构并将探索到的物体标记为“被使用”。
//这样,GC就成功找出了所有正在被使用的物体。它们将很幸运地活下来
-
回收阶段(Collection Phase) 在这个阶段,GC会从内存中“删除”所有未被引用的物体。(也就是我们上一步没发现的物体)
所谓“删除”,其实并不是真正地抹去数据。实际要简单得多:只需要将该物体所在的内存区域标记为“未使用”就可以了, 这样我们就可以继续使用这块内存做别的事情了。(原来的数据是一直存在的!)
-
压缩阶段(Compacting Phase) 经历过回收阶段的清洗之后,内存中会出现许多空隙(因为我们“删除”了许多物体)。在这个阶段,GC会把存活下来的 物体重新排列,使得它们都“沉到堆底”,从而最小化内存中的空洞。这个过程中物体之间的相对排列顺序是不变的。 到此为止,一次完整的垃圾回收就完成啦!
那么,什么时候GC会被触发呢?
(1)当可用内存快满时,或内存占用超过GC所设定的某个阈值时
(2)当我们手动调用GC.Alloc()方法
C#中的垃圾回收存在使得我们永远不会为手动清理内存而烦恼,但是因为GC清理是很耗性能的过程,我们需要谨慎地“生产垃圾”。
string s;
for(int i; i<1000; i++)
{
i+=“a”;
}
//这段代码会产出非常多的垃圾
for(int i = 0; i < mesh.vertices.Length; i++)
{
float x, y, z;
x = mesh.vertices[i].x;
y = mesh.vertices[i].y;
z = mesh.vertices[i].z;
}
//这段代码也会产出非常多的垃圾。
//这是因为mesh是一个Unity类,vertices是其中的一个数组。Unity类在每次被访问其中的数组时,都会拷贝一份新的数组给使用者。
//所以代码生产了4份vertices数组。
C# 、Mono 、.NET
.NET是一个微软为Windows推出的程序开发框架。
它包含了许多常用的类库和一个称为“Common Language Runtime”(CLR) 的运行环境;CLR提供了将C#代码翻译成机器指令的功能、内存管理功能(包括GC)、多线程功能等等。
粗略地说,我们把写好的代码一口气丢给.NET处理就可以了。
.NET虽然很强大,但其主要是运行在Windows上的。于是,为了将.NET适配到多个操作系统,Mono诞生了。
Mono是.NET的一 种多平台实现,或者说是“另外一个.NET的版本”。
Mono包含了:C#编译器、Mono Runtime(和CLR类似)、.NET类库和Mono 类库。
C#是一门用来开发基于.NET框架的软件的编程语言。(Windows:.NET本体;其他平台:Mono)
Unity作为一个多平台游戏引擎,自然需要Mono的多平台特性。 这也解释了“MonoBahaviour”这个名字的由来:“Mono”指Mono Runtime、“Behaviour”指“物体行为”。所以MonoBehaviour就是 “基于Mono Runtime的物体行为脚本”。
与大多数编程语言一样,一段C#代码需要通过层层的步骤才能转化为电脑能读懂的机器指令。
- C#代码 这是最高层的,人类易懂的语言。
- IL/CIL(Common Intermediate Language,中间语言) 当我们编译C#代码时,编译器会将其转换为跨平台的IL代码。(Windows:.exe)
- 机器码(Machine Code) 当我们运行编译好的程序时,CLR会让一个叫做JIT(Just In Time)的编译器将 IL代码编译成当前平台的机器码。这是最底层的,直接被电脑执行的代码。
泛型 Generics
泛型允许一个函数或类接受一些类型作为参数。
泛型方法 Generic Methods
首先我们来看看泛型在函数/方法上的用途。 在定义一个函数时,我们不仅用圆括号()标记所接受的变量参数,还可以用尖括号<>标记接受的类型参数。
//eg.
int Add(int a, int b)//非泛型函数
{
return a+b;
}
T AddGeneric<T>(T a, T b)//泛型函数
{
return a+b;
}
这里我们接受了一个类型变量”T”。”T”这个名字是自选的,不过一般的惯例是命名为”T”(Type)。这样,a和b两个参数的类型都是T了。
在调用泛型函数的时候,我们需要补充尖括号中的内容:float sum = AddGeneric<float>(5f, 7f);或者使用简写float sum = AddGeneric(5f, 7f);
泛型方法可以接受多个类型变量。我们在定义时需要用逗号隔开:
void Insert<TKey, TValue>(Dictionary<TKey,TValue> dict, TKey key, TValue value)
{
dict.Add(key, value);
}
调用时:Insert(dict, 2, “February”);或Insert(dict, 2, “February”);
//现在,我们可以大概推断出Unity的GetComponent方法大概是怎么被定义的了:
T GetComponent<T>()
{
T comp;
……
return comp;
}
//不过GetComponent会接受所有类型的类型参数吗?可以Get一个int类型的Component吗?
泛型的类型限制
有时我们会希望一个函数所接受的泛型变量处于某个范围之内,比如GetComponent方法只会接受Component类型的参数。
T AddGeneric<T>(T a, T b)
{
return a+b;
}
//事实上,这个函数在编译器里面是会报错的,因为“+”这个运算符,并没有在所有类型中都有定义
为了解决这个问题,我们可以在圆括号后使用where关键字对类型变量作出一些限制:
where T: struct (T必须为值类型)where T : class (T必须为引用类型)where T : new() (T必须有一个无参数的构造函数)where T :<base class name> (T是继承自一个基类的)where T :<interface name> (T实现了一个接口)
T GetComponent<T>() where T: Component //其实就是使用继承来限制
{
T comp;
……
return comp;
}
泛型类 Generic Classes
一个泛型类允许我们在创建该类的实例时传入一个类型参数。
//eg.
public class MyList<T> where T: struct
{
List<T> list = new List<T>();
public void Add(T item)
{
list.Add(item);
}
}
//这是一个接受值类型的List类。在类名的定义之后添加尖括号(以及类型限制)即可。
Coroutine 协程
协程是一个函数;定义如下:
IEnumerator <FuncName>(<Params>)
{
<content>
}
//即把一个函数的返回值改为“IEnumerator”即可
//eg.
IEnumerator MyCoroutine (float f)
{
f = 5;
}
调用协程函数:
StartCoroutine(IEnumerator routine);
不可以直接视作函数调用
协程系统还有一个很重要的组成部分:yield
-
yield关键字的作用是将一个协程暂停,并在下一帧继续执行
-
yield通常搭配return使用:yield return xxx
-
常用结构:
- yield return null:下一帧继续执行协程
- yield return new WaitForSeconds(i):在i秒后继续执行
//eg. IEnumerator DisableAfterTwoSec() { yield return new WaitForSeconds(2); gameObject.SetActive(false); } //eg. IEnumerator MyUpdate() { while(true) { DoSomething(); yield return null; } } //这个函数的功能和Unity自带的Update()函数是一样的
关于WaitForSeconds
注意WaitForSeconds是一个类!(使用new WaitForSeconds()来构造实例)
好习惯:如果在循环中多次等待同一段时间,最好先建立WaitForSeconds实例 再使用,而不是在循环中不断new。
//eg.
WaitForSeconds w1 = new WaitForSeconds(1);
while(true)
{
yield return w1;
}
Action与Func
C#中的事件系统中有两个常用的组件:Action和Func。可以把它们想象成存储了许多函 数的List。当一个Action/Func执行时,其中所有的函数都会一起执行。
Action/Func是一个类型,我们可以定义类型为Action/Func的变量并用它来存放函数。
//eg.
public Action onPlayerInjure;
void Start()
{
onPlayerInjure+=ScreenFlash;
}
Action:常用操作
Action位于namespace System中 ,它能够存放的函数必须是无返回值的(也就是void函数)
有关的常用操作有这些:
-
向一个Action中添加一个函数:“+=”
比如:
onDamage+=ScreenFlash;注意,+=右侧的值为想要添加的函数名 -
从一个Action中删除一个函数:“-=”
比如:onDamage-=UpdateHPBar;
-
调用一个Action中所有的函数:把它当作一个函数来用即可
比如:
onDamage();
Action:有参数的函数
Action够存放的函数必须是无返回值的,但是可以有参数!
每个Action类型的变量中的函数的参数必须都是相同的。
比如void A(int a) void B(float b) void C(float c) , 则B和C可以放在同个Action里,而A不行
定义一个有参数的Action:Action<参数1类型,参数2类型,……>
比如:private Action onDamage;, 这代表onDamage中的函数都是接受一个float类型的参数,且无返回值的函数
使用它的时候就可以传入一个参数了: onDamage(45.2f);
Func:有返回值的函数
Action可以用来存放void函数,那如果想要存放有返回值的函数怎么办?
这时就需要Func了! - Func和Action是同一“家族”的,而它们唯一的区别就是有无返回值。
在定义Func的时候,需要在所有参数之后加上返回值的类型:
private Func<int,float> func1; //func1中的函数接受1个int类型的变量,并返回float
private Func<string> func2; //func2中的函数不接受变量,返回string
private Func<int,int,int> func3; //func3中的函数接受2个int类型的变量,并返回int
private Func func4; //func4会报错
// 使用Func的时候,当一个普通的有返回值的函数即可
//eg.
private Func<int, int, int> add;
···
int sum = add(4,5);
委托 Delegate
Action和Func背后隐藏着一个强大的机制:委托。委托提供的功能正是“可以存放函数的类型”。
delegate int Calculate(int x, int y);
这样,我们就定义了一个委托类型。这个类型的变量中可以存放返回值为int且接受两个int参数的函数。
delegate <返回值类型> <委托类型名>(<参数列表>);
这是通用的模板。
上方我们只是定义了一个类型。当我们想要使用委托时,需要声明一个该类型的变量。
//eg.
Calculate cal; //声明委托类型的变量
cal = AddInt; //将AddInt函数装进变量
int sum = cal(6, 7); //使用委托
int AddInt(int x, int y)
{
return x+y;
}
float AddFloat(float x, float y)
{
return x+y;
}
多播委托 Multicasting
一个委托变量中也可以存储/调用多个函数。这叫做Multicasting。
Calculate cal;
cal += AddInt; //我们可以使用+=运算符向委托变量中添加函数,
cal += MinusInt;//同样可以使用-=运算符除去函数。
当一个装有多个函数的委托变量被调用时,其中的函数会被依次调用,且:
- 如果参数中有引用类型的变量,该变量会依次受到这些函数的影响。
- 如果函数有返回值,则最终返回最后一个函数的返回值。
一个委托类型中的函数们叫做调用列表(Invocation List)。我们可以通过GetInvocationList()获取它:
cal.GetInvocationList();
cal.GetInvocationList().Length; 这样可以获取其中函数的数量。
//eg.
delegate int Calculate(int x, int y);
public static void Main()
{
Calculate cal = null;
cal+=Add;
cal+=Add;
int sum = cal(1,1);
Console.WriteLine(sum);
}
private static int Add(int x, int y)
{
return x+y;
}
//output:2
事件 Event
事件(event)是对委托的一层封装。它允许我们更方便地在不同的类之间“发送提醒”。
粗略地看,事件就是一个仅支持“+=”和“-=”的委托。这么做禁止了“=”,也就是不可以直接修改该委托的invocation list。 我们可以用event关键字修饰一个委托变量来将其变成事件变量。用法与委托大体一致。
//eg.
public delegate void MyDelegate(string message);
public event MyDelegate MyEvent;
…
MyEvent+=xxx;//这是可以的
MyEvent-=xxx; //这也是可以的
MyEvent = xxx; //这不可以
Action 和 Func的实质
Action就是一个无返回值的,接受0-16个参数的委托。
public delegate void Action();
public delegate void Action(T obj);
public delegate void Action(T1 arg1, T2 arg2);
而Func就是一个有返回值的Action。
public delegate TResult Func();
public delegate TResult Func(T arg);
public delegate TResult Func(T1 arg1, T2 arg2);
in、out关键字:
in: 该参数不会被 函数修改 out:该参数会被 传输至函数外
字段 Field、属性 Property
字段是类中的成员变量,private int speed = 5;
很多时候,我们不希望其他类直接访问我们的字段。或者我们希望每次访问一个字段时可以做一点事。 属性(Property)提供了这个功能。
属性可以理解为一个对字段的封装,它能给一个字段添加一些功能:比如读写限制、读 写时执行函数等等。 一个属性具有两个组成部分:getter与setter。它们分别定义了读、写该属性的行为:
//eg.
private int speed = 5;//事实上什么也没做
public int Speed
{
get{return speed;}
set{speed = value;}
}
//属性变量通常用于保护一个字段,为一个私有变量提供一个经过封装的公开访问通道。比如这里的Speed实则是一个对speed的封装。
属性:Getter
//eg.
private int speed = 5;
public int Speed
{
get{return speed;}
}
属性的Getter定义了读取该属性的行为。Getter必须有返回值。 它看上去就像调用了一个函数并将函数的返回值给读取者。 语法:get{<函数语句>}
Getter的存在允许我们自定义读取某变量时的行为,它增加了类的安全性与可读性。
属性:Setter
//eg.
private int speed = 5;
public int Speed
{
set{speed = value;}
}
属性的Setter定义了写入该属性的行为。Setter有一个看不见的参数 “value”。value代表我们要写入的那个值。 它看上去就像调用了一个函数并将在函数中修改了字段。 语法:set{<函数语句>
自动属性
public int Speed { get; set; }
与其写出完整的getter和setter,我们只需要写get;set;就可以自动获得默认的getter和 setter。
通过这种方式,我们可以轻易地控制一个属性的可读/写性。
public int Speed//可读,不可写
{ get; }
public int Speed//可读,但只有本类可写
{ get; private set;}
public int Speed//可读,但只有本类和子类可写
{ get; protected set;}
//属性不可以为“可写但不可读”。
接口 Interface
接口(Interface)定义了一系列类的规范。接口中可以包括方法、属性、事件等成员,而这些成员必须被其子类实现。
//eg.
public interface IDamageable
{
float hp {get; set;} //属性:生命值
void OnDamage(float value);//方法:受击
}
接口很像是一个“未完成的类”。在定义方法时,我们完全不用 (也不可以)写方法的主体;
在定义属性时,我们也不可以给其赋予初始值。 它只是一个“接口”,等待子类接入并真正实现这些成员,以此来确保所有的子类都有这些实现。
和一般的类一样,我们可以让一个类继承自接口。与类不同的是,我们可以继承自多个接口。
//eg.
public class Enemy : IDamageable, IHittable
{
//这里必须实现所有接口的成员,否则会报错!
}
实现一个接口相当于补充接口中所有属性与方法的实现。
public interface IDamageable
{
float hp {get; set;} //属性:生命值
void OnDamage(float value);//方法:受击
}
public class Enemy : IDamageable
{
public float hp { get; set; }
public void OnDamage(float value)
{
hp-=value;
}
}
//Enemy类实现了接口中所有的属性与方法。这是必须完成的任务。
部分类 Partial Class
部分类允许我们把同一个类写在多个文件里,每个文件提供类的一部分。 定义时使用partial关键字。
//Map.cs
public partial class Map
{
private float hp { get; set; }
}
//MapAddHp.cs
public partial class Map
{
public void AddHP(float value)
{
hp += value;
}
}
//Map类被定义在了两个文件中,但其实际的功能和直接写在一起是一样的
Lambda 表达式
Lambda表达式是一种允许我们“快速定义函数”的方法。可以把一个lambda表达式想象成一个简易函数。
expression lambda
(参数列表) => (返回的表达式)比如(x,y)=>x*y
上方右侧表达式的含义和这个函数类似:
T MyFunc(T x, T y)
{
return x*y;
}
注意lambda表达式是没有函数名的, 所以也被称为匿名函数。
使用lambda表达式时把它当作一个委托类型的变量即可,比如(x,y)=>x*y就可以是类型为Func<int,int,int>的变量。所以我们可以这么写:Func<int,int,int> mul = (x,y) => x*y;
statement lambda
statement lambda可以没有返回值。
(参数列表) =>
{
执行的程序语句
}
//eg.
(go) =>
{
go.SetActive(false); //这里写任何语句都可以
}
一个没有返回值的statement lambda可以理解成一个Action类型的变量。
Action<string> greet = name =>
{
string greeting = "Hello {name}!";
Console.WriteLine(greeting);
};
greet("World");
//output:HelloWorld
作为参数的函数
有了lambda表达式后,我们就可以轻松地把函数作为参数传入其他函数了! 只需定义一个Action/Func参数即可。
IEnumerator DelayedCall(Action action, float seconds)
{
yield return new WaitForSeconds(seconds);
action();
}
//这样调用
StartCoroutine(DelayedCall(() =>
{
Destroy(gameObject);
}, 2.0f));